Austin LasseterHow to share your work on DeepnoteIf you haven’t tried it yet, don’t walk — Run! and checkout Deepnote, the best free platform for hosting your data science projects. And…Feb 25Feb 25
Austin LasseterA quick analysis using DeepnoteI’ve always loved jupyter notebooks, but I recently stumbled upon a new way to share them — Deepnote is easily the best free jupyter…Feb 24Feb 24
Austin LasseterConvert your Python apps from Heroku to the AWS Free TierA lot of us are very disappointed to hear the recent news that Heroku is going to discontinue its free service. Heroku has been a great…Aug 30, 2022Aug 30, 2022
Austin LasseterDeploying from Sagemaker Studio Lab using DockerIn a previous blog post, I talked about how to deploy applications using the Heroku CLI. The purpose of this post is to demonstrate…Jul 3, 2022Jul 3, 2022
Austin LasseterInstalling the Heroku CLI on AWS Sagemaker Studio LabTogether, SMSL and Heroku make a powerful (and free!) combination that makes it easy to develop and deliver machine learning applications.Jun 13, 2022Jun 13, 2022
Austin LasseterCloning your first repo to Amazon Sagemaker Studio LabAmazon SageMaker Studio Lab is a free machine learning (ML) development environment that provides the compute, storage (up to 15GB), and…Jun 10, 20221Jun 10, 20221
Austin LasseterHow to display Plotly visualizations in Amazon Sagemaker Studio LabAmazon SageMaker Studio Lab is a free machine learning (ML) development environment that provides the compute, storage (up to 15GB), and…Jun 9, 2022Jun 9, 2022
Austin LasseterGetting started with free AWS Sagemaker Studio LabAmazon SageMaker Studio Lab is a free machine learning (ML) development environment that provides the compute, storage (up to 15GB), and…May 26, 2022May 26, 2022
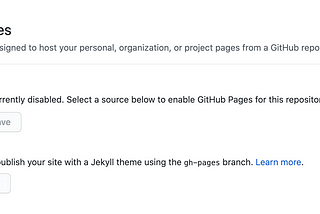
Austin LasseterCreate a static webpage using Github and PlotlyAs a data scientist, you often create visualizations that tell a story about your data. But you may feel limited by the fact that these…May 25, 2021May 25, 2021