Deploy an NLP classification model with Amazon SageMaker and Lambda

Introduction
Note: You can view this tutorial as a video on youtube.
How does a machine learning engineer make their model results accessible to end-users via the web? This once-daunting task is now pretty straightforward using a combination of AWS services, especially SageMaker and Lambda.
Amazon SageMaker is a powerful tool for machine learning: it provides an impressive stable of built-in algorithms, a user interface powered by jupyter notebooks, and the flexibility of rapidly training and deploying ML models on a massive range of AWS EC2 compute instances. But even the most accurate model provides no benefit if it’s inaccessible to other people! Our end-users can’t log into our SageMaker instance and run our notebooks, so it’s important to connect our finished model to a web-facing application. In this way, potential clients can benefit from the accuracy of our model’s predictions. That’s where SageMaker endpoints Lambda comes in — it’s the bridge that connects our SageMaker endpoint to our front-end web app.
Here’s what we’re going to build:

Let’s dive in and see how to do this.
Amazon SageMaker and the ML workflow
The typical machine learning workflow is an iterative process consisting of three major steps in an ongoing cycle:
- Generate data
- Training
- Deployment
Not too long ago, each of these steps required a different set of tools and domain knowledge. By and large, data scientists stopped at model evaluation, and didn’t venture into the realm of DevOps for deployment. Now, Amazon SageMaker provides a single platform that integrates all three steps of this cyclical workflow.

Let’s start with a pretty straightforward machine learning problem — text classification. We’ll briefly review the steps involved in setting up the data and training the model, and then move into how we can deploy our trained model and make it accessible via a web application.
Text Classification with SageMaker BlazingText
BlazingText is one of the latest built-in algorithms provided by Amazon SageMaker. It’s an unsupervised learning algorithm for generating Word2Vec embeddings, and can be used to solve typical NLP problems like sentiment analysis, named entity recognition, machine translation, etc.
In this blog post, we’ll focus on a specific problem, multi-label classification of user-provided responses. Using the DBPedia Ontology dataset as our training data, we’d like to build an application that allows users to classify any text according to one of 14 different labels.
Let’s assume you already have some familiarity SageMaker — if not, check out this tutorial from Amazon. As with any SageMaker job, let’s start by specifying four objects at the top of our notebook:
sess = sagemaker.Session()
bucket = sess.default_bucket()
role = get_execution_role()
region_name = sess.region_name- The SageMaker session — this provides convenient methods for manipulating the entities and resources that Amazon SageMaker uses, such as training jobs, endpoints, and input datasets in S3.
- The S3 bucket and prefix where our data will be stored. If you’re using SageMaker for the first time, you may be surprised to learn that you’ll have to store your data on S3 before you can use it to train your model!
- The IAM role used to give SageMaker access to our data. When we build our training job later we will need to tell it what IAM role it should have. This role can be obtained using the
get_execution_rolemethod from thesagemakerSDK for python. - The Amazon region where our notebook is hosted — this must be the same region as our S3 bucket. Note that we can call this as an attribute of the
Sessionobject we created earlier.
We’ll use these objects throughout our code, so it’s important to establish them up front and understand what they do. If you’re a data scientist coming from a non-AWS background and you’re using SageMaker for the first time, you’ll probably be unfamiliar with these objects and it’s a great idea to refer to the SDK documentation for a full read-through.
Following the standard playbook for any NLP classification task, we’ll need to prepare our data using the following steps — check out our notebook for details on how to carry them out, with an eye to what’s unique in SageMaker.
- download the DBPedia dataset from the web onto our SageMaker instance.
- preprocess the text data — we’ll initially do this with NLTK, a standard toolkit for tokenizing and preprocessing text. But we’ll need to revisit this later on, in the context of our web app, as NLTK won’t be available to us in AWS Lambda.
- as a requirement of BlazingText, our class labels should be prefixed with
__label__. - split the data into training, validation and testing sets.
- upload the processed datasets to our S3 bucket so they can be used for training and evaluating our model.
Note that we don’t need to vectorize our tokenized text (which would be a typical step in other NLP workflows) as the BlazingText algorithm will handle this step for us automatically, using Word2Vec.
Training our classification model
When a training job is constructed using SageMaker, a container is executed which performs the training operation. This container will expect to read in data that is stored only in S3 — that’s why we had to upload the datasets to our S3 bucket, rather than simply keeping them on our local instance as we might have done in our pre-AWS days. It’s not a bad idea to jump over to the S3 console, just to get a visual confirmation of where our data is now stored. for our DBPedia BlazingText example, we should see a three separate subfolders for output, train and validation data, like this:
Now that we have the training and validation data uploaded to S3, we can construct our BlazingText model and train it. We’ll be making use of the SageMaker SDK for Python, which will make our code more readable but somewhat less flexible. The first step is to instantiate our BlazingText estimator, as follows:
container = sagemaker.amazon.amazon_estimator.get_image_uri(region_name,
"blazingtext", "latest")To use the get_image_uri method we need to provide our current region, which we obtained earlier from the session object, and the name of the algorithm we‘re using (in this case, BlazingText).
Keep in mind that SageMaker uses Docker containers to train and deploy algorithms. For me, as a new user of SageMaker, the practice of calling prebuilt containers was a major paradigm shift from my previous ML workflow. I was used to building my models locally, using virtual environments and python libraries I’d installed on my own GPU, which I then had to constantly manage and keep up-to-date. It’s worth taking a deep dive into how and why Amazon instituted containers as part of its machine-learning workflow for SageMaker. Suffice to say that working in a containerized environment provides greater flexibility, better security and broader access to a range of ML models, without the hassle or expense of buying a GPU, maintaining multiple virtual environments, patching the OS, etc. Honestly, once I shifted to containers on SageMaker I felt like I’d finally gotten my ticket out of dependency hell.
Once we’ve established the container that hosts our algorithm, we need to instantiate our Estimator object. This is an object of the SageMaker SDK that houses our algorithm. Amazon SageMaker provides several built-in machine learning algorithms that you can use for a variety of problem types, or you can build your own custom estimator. In this case, our estimator will be BlazingText. When we instantiate our estimator, we’ll need to pass it several parameters, including (but not limited to):
- our IAM role (established above);
- the count, type, and volume size of our EC2 instance;
- the path to S3 where we’ll store our model outputs;
- the input mode (
Fileis appropriate for smaller, static input like ours, whilePipeis better for large or streaming data).
bt_model = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type= 'ml.c4.4xlarge',
train_volume_size = 30,
input_mode= 'File',
output_path=s3_output_location,
sagemaker_session=sess)Take special note of the EC2 instance type we’re calling here — it makes a big difference! On the one hand, we want to call a compute instance powerful enough to handle our training dataset. On the other hand, we want to keep our cost as low as possible. Finding this balancing point is a fine art! Make sure you refer to the SageMaker pricing page before selecting your model. Fortunately, though, once the training job finishes, SageMaker will shut this instance down — so that will help to keep us from running up an unexpected bill after our work is done.
As with any ML model, it’s also highly recommended to established your preferred hyperparameters — or better yet, use SageMaker’s automatic hyperparameter tuning and save yourself the trouble!
We’ll also need to set up the connection between our data channels and our estimator. To do this, we’ll create three separate sagemaker.session.s3_input objects, one for each of the data channels that we set up earlier on our S3 bucket were we stored our three datasets: train, validation and test.
Now that we have our estimator object completely set up, it’s time to start training! To do this we make sure that SageMaker knows our input data is in the proper format — which in the case of BlazingText is a space-separated file intext/plain format— and then we execute the fit method. We’ll ask SageMaker to print out the data logs using the logs=True parameter so that, for every epoch, we can view the accuracy of our model on the validation data.
train_data = sagemaker.session.s3_input(s3_train_data,
distribution= 'FullyReplicated',
content_type='text/plain',
s3_data_type='S3Prefix')validation_data = sagemaker.session.s3_input(s3_validation_data,
distribution='FullyReplicated',
content_type='text/plain',
s3_data_type='S3Prefix')data_channels = {'train': train_data, 'validation': validation_data}
bt_model.fit(inputs=data_channels, logs=True)
Once training is complete, the logs will provide the following information about our model:
#train_accuracy: 0.9869
Number of train examples: 112000
#validation_accuracy: 0.9723
Number of validation examples: 70000Our validation accuracy on the DBPedia dataset is excellent! BlazingText strikes again. The trained model — referred to as a model “artifact” — can now be viewed in the SageMaker console, but it’s actually stored in the S3 bucket that was set up as theoutput_path when we instantiated our estimator. It’s a good sanity check to actually hop over to the S3 console and view it there:
Deploy the trained model to a SageMaker endpoint
Now that we’ve built our model, and we’ve stored it on S3, we can use it to make predictions on new data! To do this, we’ll need to deploy an endpoint.
The steps for deploying an endpoint are pretty similar to training our model — but with a few important differences. The most important is the size of the EC2 instance we choose for deployment. Unlike our testing instance, the deployment instance won’t automatically shut down — it will keep running until we tell it to stop! This can result in some pretty big charges if you’re not careful. Choose your deployment instance carefully, and keep it on only as long as you need it! Refer to the SageMaker pricing page for details. Notice that in the code below, I selected the cheapest possible instance type for my deployed model (only $0.065 per hour) because I plan to keep it on long enough for you to read this article!
text_classifier = bt_model.deploy(initial_instance_count = 1,
instance_type = 'ml.t2.medium')Another important difference is the format of our data. While BlazingText expected our training data to be formatted according to the text/plain content type, it actually requires our inference data to be in the application/json content-type. Our endpoint will expect to receive a list of sentences in JSON format, with "instances" as the JSON key. We’ll discuss this in a little more detail below, when we present our Lambda function.
Once the model is deployed, we can make predictions using new data inside the SageMaker notebook if we wish.
As a final step in our SageMaker notebook, we need to find out the name for our deployed SageMaker endpoint. We’ll print this information in our notebook, and copy it down for later use in our Lambda function.
print(text_classifier.endpoint)
>> 'blazingtext-2020-XX-XX-XX-XX-XX-101'This endpoint is encrypted for security, so it can’t be called outside of our notebook without proper authentication.
Making use of the deployed model
Up to this point, we’ve successfully trained and deployed our model on SageMaker. But as we stated at the beginning — our goal is to share our model with our users, so that they can make their own predictions! As a result, it’s not enough just to make inferences inside our jupyter notebook. We need to find a way to share our model on the web using an interactive app that doesn’t require our users to have any specialized knowledge of machine learning or cloud computing. To do this, we’ll need to connect our SageMaker endpoint to a serverless function using AWS Lambda and API Gateway, as described in this blog post from AWS.
The combination of AWS services in our input/output stream will look like this:
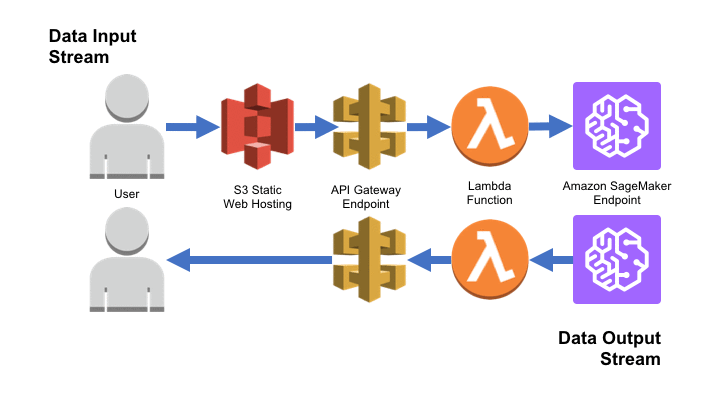
While most of the steps in this process are pretty straightforward, let’s describe our Lambda function in more detail. We will need to give this function permission to send and receive data from our SageMaker endpoint.
How Lambda talks to SageMaker
The central piece of our architecture is our Lambda function: it is the bridge between our machine-learning model and our user-facing web-application. The Lambda function must receive text data from the user, preprocess it, pass it to our SageMaker endpoint, and then return the predictions back to the user in a readable format. You can view the complete function here, but let’s break it down step-by-step. Hat-tip to Cezanne Camacho for writing this function for us! I learned it from her.
As we create our Lambda function, we begin by providing it an IAM role that allows it to share data with other AWS services. Remember that our SageMaker endpoint is secured, meaning that only entities that are authenticated with AWS can send or receive data from our deployed model.
To handle this authentication properly, we’ll need to create an IAM role for our Lambda function that provides full access to our SageMaker endpoint. Here’s a quick image of what that looks like in the IAM console, but you’ll want to read all the details of setting up your Lambda function with IAM here.

Let’s take a deeper look at our Lambda function as it appears in the Lambda console:
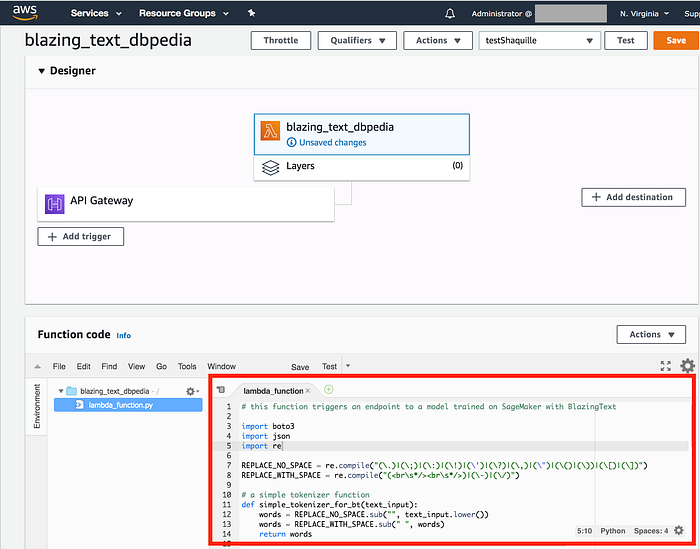
We begin with importing a few python libraries — the most important of these is boto3, the SDK that allows python developers to interact with all AWS services. It’s important to note that, unlike our jupyter notebook on SageMaker, our Lambda function won’t have access to either the SageMaker SDK we used earlier, or the NLTK library we used to preprocess our data.
Next we define a simple function for tokenizing and preprocessing the input text data. Remember that when we built our training model, we first had to simplify it as a list of word tokens. This same preprocessing needs to be done to our user input as well. While a more robust tokenizer like nltk.word_tokenize might improve the accuracy of our model somewhat, we’ll content ourselves with just removing unnecessary punctuation and reducing words to lowercase. Remember that BlazingText expects all tokens as space-separated, so we’ll include that step in our preprocessing function!
def simple_tokenizer_for_bt(text_input):
words = REPLACE_NO_SPACE.sub("", text_input.lower())
words = REPLACE_WITH_SPACE.sub(" ", words)
return wordsFor inference, the BlazingText model accepts a JSON file containing a list of sentences; each sentence should be a string with space-separated (not comma-separated) word tokens.
{ "instances": ["regina spektor is my favorite musician because she plays the piano", "the burj khalifa is the tallest skyscraper in the world"] }Next we define the lambda_handler function, which is an essential component of any Lambda function. Note that it expects the following arguments:
event– AWS Lambda uses this parameter to pass in event data to the handler.context– AWS Lambda uses this parameter to provide runtime information to your handler.
Our function will receive the user’s input data as the event, then process it with the tokenizer function we defined earlier. We then format the tokenized text according to JSON format, as expected by BlazingText.
At this point, we’re ready for Lambda to call the SageMaker endpoint we established earlier. But to do this, we’ll need to know our runtime, which is what is allows us to invoke the endpoint. We can get the runtime by calling the boto3 SDK as follows:
runtime = boto3.Session().client('sagemaker-runtime')Now that we know the runtime, we can go ahead and invoke our endpoint in order to get the predicted labels for our user’s text. We do this by calling the invoke_endpoint method on our runtime, as follows:
response = runtime.invoke_endpoint(
EndpointName = 'blazingtext-2020-XX-XX-XX-XX-XX-101',
ContentType = 'application/json',
Body = json.dumps(payload))Remember that we copied down the name of our SageMaker endpoint earlier, which is now provided as the parameter EndpointName in our lambda function. As mentioned above, BlazingText requires the content to be formatted as application/json (note that this is not true of other SageMaker algorithms such as XGBoost).
The output of our invoked endpoint is a JSON object whose primary component, Body, must be decoded into a more readable format. This object contains the predictions for our input data! In this case, we’ll break it into two parts — label and probability — which we’ll then feed into a formatted python text string.
output = json.loads(response['Body'].read().decode('utf-8'))
prob = output[0]['prob'][0]*100
label = output[0]['label'][0].split('__label__')[1]
final_output = 'The predicted label is {} with a probability of {:.1f}%'.format(label, prob)The last step of our Lambda function provides a nice segue into the next phase of our application workflow. Our function returns a JSON object with three keys — statusCode, headers, and body — because this is the HTTP format expected by the POST request in API Gateway.
return {'statusCode' : 200,
'headers' : { 'Content-Type' : 'text/plain',
'Access-Control-Allow-Origin' : '*' },
'body' : final_output
}Before moving ahead, it’s a good idea to test our function inside the Lambda console — this will allow us to troubleshoot any issues before they have downstream consequences. In the top right of the Lambda console, choose “configure test event” and in the dialogue box that opens, supply a JSON object like the one below as an example of input user data.
{"body": "Walter Perry Johnson was a Major League Baseball right-handed pitcher. He played his entire 21-year baseball career for the Washington Senators."}Save the test event and then try it out using the “test” button in the top right of the console. If everything is working as expected, your test event should generate a response with a 200 status code and a successful prediction!
{
"statusCode": 200,
"headers": {
"Content-Type": "text/plain",
"Access-Control-Allow-Origin": "*"
},
"body": "The predicted label is Athlete with a probability of 94.0%"
}If you don’t get a 200 status code, or your predictions are wrong, you might need to do some additional troubleshooting either in your Lambda function or back in SageMaker itself. One problem I ran into was that, in an early iteration of my Lambda function, I was processing the text data using the same steps as I had used with the training model. But as we’ve seen, the deployment model actually expects preprocessing to use a different format. Troubleshooting steps like this will help you better understand your own code!
API Gateway
The next step in our architecture is to build an HTTP endpoint that will allow our back-end Lambda function to talk to our front-end web app. To do this, we’ll use another AWS service, API Gateway.
The details of how to set up the API Gateway are outside the scope of this tutorial, but don’t worry! It’s not complicated. Check out this blog post for an easy walk-through of what you’ll need to do. Once you’re finished building the endpoint, you should test it out in the API Gateway console like this:
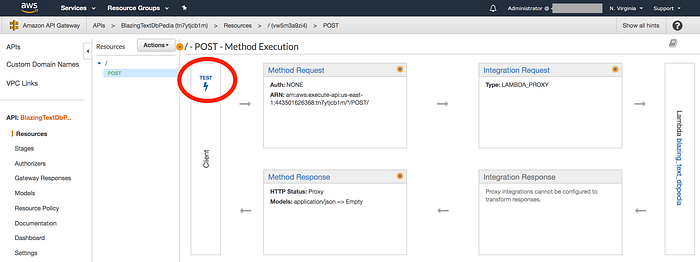
In the dialog window that opens, try passing the API some test data similar to the sentences we tried before. You should get a response similar to this one:

Note that the new HTTP endpoint we created just now is different from the SageMaker endpoint we built earlier! While the SageMaker endpoint was fully encrypted, making it inaccessible without proper authentication, the endpoint we construct with API Gateway will be open to the public internet. Whenever a user sends data to our public endpoint, it will trigger our Lambda function, which as we’ve seen will send the input to our SageMaker endpoint and then return the resulting predictions back to the public endpoint.
Don’t worry! Our model and its underlying data are protected by the IAM role we assigned to our Lambda function — the HTTP endpoint and its users will only have access to the results of our model, not the model itself.
We’ve now successfully set up a public API that lets us access our Lambda function, which in turn will access our SageMaker model. Let’s make a note of the URL provided by API Gateway to invoke our endpoint— we’ll need this in the next and final step.
Host the app on an S3 bucket
Now that we have a publicly available API, we can start using it in a web app. While a good front-end developer could really jazz things up, for this blog post we’ll content ourselves with building a simple, bare-bones application that uses rudimentary HTML and javascript — no CSS styling here!
In our github repo there’s a file called index.html that is originally taken from Cezanne Camacho’s repo, as part of her ML course on Udacity. With a few modifications, we’ve updated that file for use with our BlazingText example. Let’s download and open the HTML file using a text editor on our laptop. Take note of the following at line 64:
action="https://XXXXXXXXXX.execute-api.us-east-1.amazonaws.com/prod"This is the production endpoint for my version of the public HTTP endpoint. You’ll need to replace this string with the URL you got from the previous step, and then hit save. Now go ahead and open index.html in your browser— this will convert your laptop into a local web server and you can take a look at the app in all its glory!
But don’t stop yet, there’s one step left to go. In order to share our work with the whole world, we need to host our HTML file as a static website on Amazon S3. I’ve written a couple of blog posts explaining how I learned to do this — you can start with the simple version, or you can go a little further and use Lambda and CloudFront to give your website some additional security and elasticity. Either way, you’ll find it’s pretty straightforward to host your index.html file as a website on S3.
You can view my finished application here. Go ahead and try playing around with different text inputs — see if you can tinker with the text input to get a variety of successful predictions from BlazingText!
Remember that the model was trained on text data from DBPedia, so it will respond best to text input that’s similar to articles on wikipedia. Personally, I’ve found it pretty easy to predict labels like Artist, Athlete, or Means of Transportation, but it’s a little harder to get it to identify Village, Album or Educational Institution. I’ll let you be the judge :)
And that’s a wrap! Congratulations, we’ve trained a machine learning model for multi-label text classification, and we’ve deployed our working model as a publicly accessible web application. To do this, we used Amazon SageMaker and AWS Lambda, along with other AWS services like IAM, S3, and API Gateway. Give yourself a pat on the back!
If you’re looking for additional practice deploying applications to the cloud, please check out my other tutorial posts on Medium and github:
- Getting started with Plotly Dash
- How to deploy a simple Plotly Dash app
- Resize an image using AWS S3 and Lambda
- How to host a static website on an Amazon S3 bucket
- Build a password-protected website using AWS CloudFront, Lambda and S3
- Deploying a python app with plotly dash and AWS elastic beanstalk
- Plotly Dash and the Elastic Beanstalk Command Line
Finally, just wanted to acknowledge how indebted I am to Emily Webber for her explanation about how to train and deploy NLP models using BlazingText. Much of my code is forked from the github repo of her course, “Architecting For Machine Learning on Amazon SageMaker.” For the deployment of the web application, I relied on materials taken from the excellent Udacity Machine Learning Engineer nanodegree program, as shared on github by Cezanne Camacho.
The app I built for this post is simply combining the great materials from these two amazing educators, to produce something a little new. I have borrowed liberally from the code they provided in class, and while the mistakes are my own, anything useful in this blog post is entirely due to their good work. Gratias tibi ago.
